5. 共识算法
5.1. 共识算法简介
共识算法是指在分布式场景中,多个节点为了达成相同的数据状态而运行的一种分布式算法。 在分布式场景中,可能出现网络丢包、时钟漂移、节点宕机、节点作恶等等故障情况,共识算法需要能够容忍这些错误,保证多个节点取得相同的数据状态。
根据可容忍的故障类型的不同,可以将共识算法分为两类:
容忍宕机错误类算法(crash fault tolerant consensus algorithm),可以容忍网络丢包、时钟漂移、部分节点宕机这种节点为良性的错误。常见算法有 Paxos、Raft。
容忍拜占庭错误类算法(byzantine fault tolerant consensus algorithm),可以容忍部分节点任意类型错误,包括节点作恶的情况。常见算法有 PBFT、PoW、PoS等。
根据使用场景的不同,又可将共识算法分为公链共识、联盟链共识两类。
5.1.1. 公链共识
公链的特点是节点数量多且节点分布分散,主要使用的共识算法有PoW和PoS,这两种共识的优点是可以支持的节点数量多,缺点是TPS较低和交易确认时间长。
5.1.2. 联盟链共识
联盟链的特点是节点之间网络较为稳定且节点有准入要求,根据需要容忍的错误类型可以选择Raft和PBFT类算法,这类算法的优点是TPS较高且交易可以在毫秒级确认,缺点是支持的节点数量有限,通常不多于100个节点。
5.1.3. 公链共识和联盟链共识的对比
| 共识 | 支持的节点数量 | TPS | 交易时延 |
|---|---|---|---|
| 公有链共识 | 10000+ | 10+ | 10min+ |
| 联盟链共识 | 100+ | 1000+ | 1s+ |
5.1.4. 长安链中的共识
目前,长安链支持Solo,Raft,TBFT,Maxbft,DPoS,ABFT 六种共识类型。六种共识对比如下:
| 共识类型 | 故障节点数为n(n>=0)时,网络中最少节点数 | 使用场景 |
|---|---|---|
| Solo | Solo只支持1个节点 | 主要用于测试及搭建demo |
| Raft | 2n+1 | 联盟链中不需要考虑恶意节点,且需要性能较高的场景 |
| TBFT | 3n+1 | 联盟链中需要考虑恶意节点的场景 |
| Maxbft | 3n+1 | 联盟链中需要考虑恶意节点的场景 |
| DPoS | 3n+1 | 公链、联盟链中存在大量参与方,又希望在考虑恶意节点情况下保持较高tps的场景 |
| ABFT | 3n+1 | 异步网络模型下,也考虑恶意节点的场景 |
5.2. Solo
5.2.1. 算法简介
SOLO是单节点无共识投票过程的“共识算法”。
5.2.2. 算法用途
快速部署单节点运行,降低试用门槛;
供开发人员进行除网络和共识模块的全流程测试。
5.2.3. 如何使用算法
部署一个长安链节点,将链配置的共识算法进行如下修改,清除数据启动即可:
#共识配置
consensus:
# 共识类型(0-SOLO, 1-TBFT, 3-MAXBFT, 4-RAFT, 5-DPOS, 6-ABFT)
type: 0
5.3. Raft
5.3.1. 算法简介
Raft算法是目前使用最广泛的非拜占庭容错类共识算法。 Raft算法主要依靠投票机制和日志复制机制来实现节点间的共识。节点通过投票选出一个leader,由leader负责处理所有请求,再将请求以日志的方式复制到其他节点。
5.3.2. 算法用途
不考虑恶意节点的多节点环境;
需要支持高TPS的环境。
5.3.3. 共识接口说明
Raft 实现了长安链的ConsensusEngine接口。
Start 方法用来初始化Raft内部状态及启动Raft实例。
Stop 方法用来停止Raft实例。
ConsensusState接口封装了节点共识状态的查询方法。
type ConsensusEngine interface {
// Init starts the consensus engine.
Start() error
// Stop stops the consensus engine.
Stop() error
// ConsensusState get the consensus state
ConsensusState
}
// ConsensusState get consensus state
type ConsensusState interface {
GetValidators() ([]string, error)
GetLastHeight() uint64
GetConsensusStateJSON() ([]byte, error)
GetConsensusType() consensuspb.ConsensusType
GetAllNodeInfos() []consensuspb.ConsensusNodeInfo
}
5.3.4. Raft共识与核心引擎交互图
流程图如下:
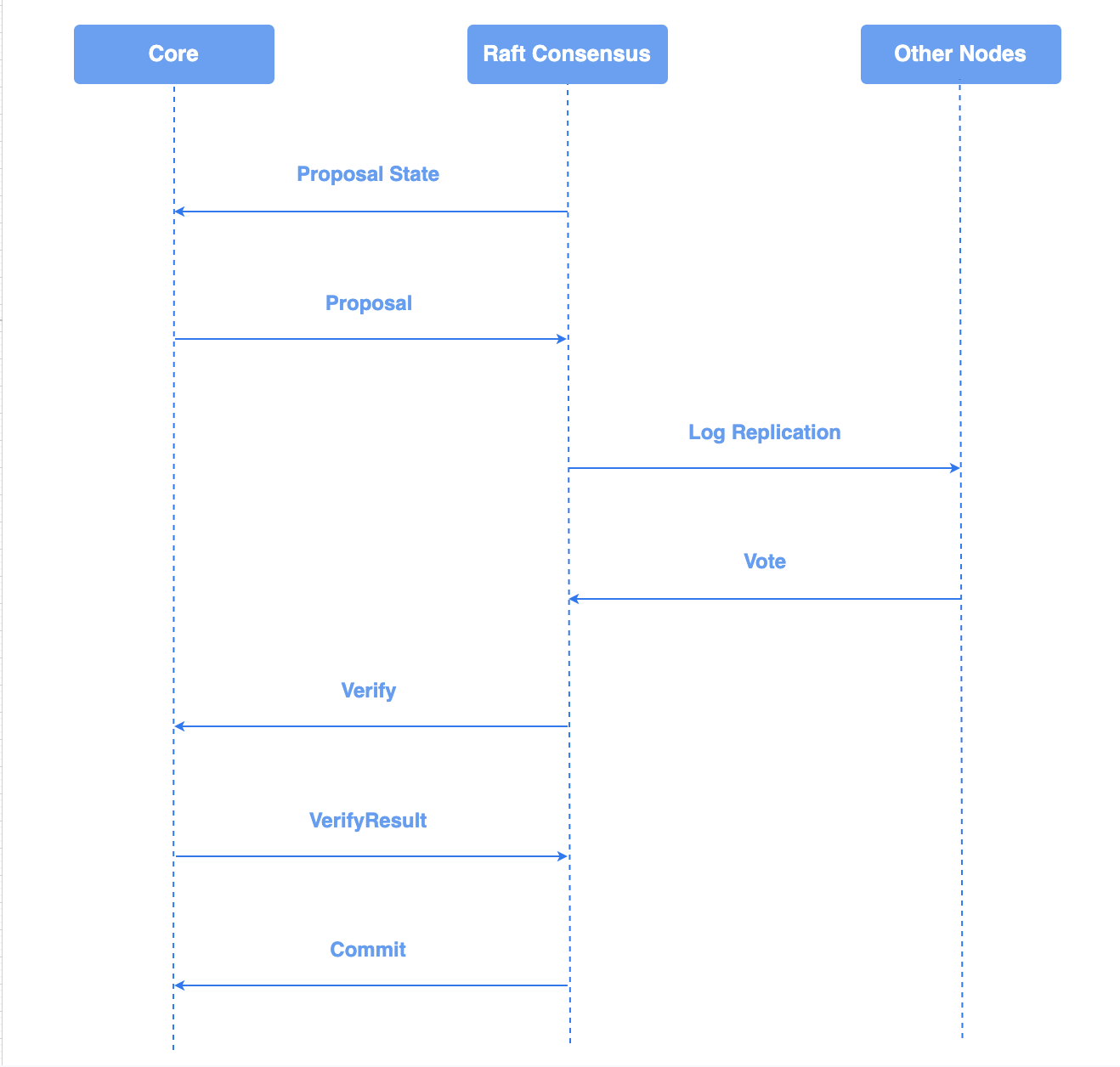
5.3.5. 如何使用算法
Raft共识建议配置节点数为2n+1(n>=0),将链配置(参见配置模块,链配置章节)的共识算法进行如下修改,清除数据启动即可:
#共识配置
consensus:
# 共识类型(0-SOLO, 1-TBFT, 3-MAXBFT, 4-RAFT, 5-DPOS, 6-ABFT)
type: 4
nodes:
- org_id: "wx-org1.chainmaker.org"
node_id:
- "QmcQHCuAXaFkbcsPUj7e37hXXfZ9DdN7bozseo5oX4qiC4"
- org_id: "wx-org2.chainmaker.org"
node_id:
- "QmeyNRs2DwWjcHTpcVHoUSaDAAif4VQZ2wQDQAUNDP33gH"
- org_id: "wx-org3.chainmaker.org"
node_id:
- "QmXf6mnQDBR9aHauRmViKzSuZgpumkn7x6rNxw1oqqRr45"
5.3.6. 共识状态查询
5.3.6.1. 查询共识节点状态
./cmc consensus status --sdk-conf-path=testdata/sdk_config.yml
{
"Height": 2,
"CommittedHeight": 1,
"Proposer": "QmSujaGs5dWBpypcHPPEgcFBjmZjW7mgg19z4rgZV33Zmq",
"Validators": ["QmR5iGwXfkKwKWimuioTKEZNrEWRBsAAfueB8FncH5EhmY", "QmSujaGs5dWBpypcHPPEgcFBjmZjW7mgg19z4rgZV33Zmq", "QmYEQZN875VbR18YK9EYJc4zXJ6vZbQvdUjcBqqWA7rrsk", "QmYrYkQsZz5R6XLxCZ1TXoeaGss5ccQfJnBtCDU6RAw8zR"]
}
返回状态说明
Height:节点正在共识的区块高度
CommittedHeight: 节点已经提交的区块高度
Proposer: 当前节点所在任期内被选举为leader的节点身份标识
Validators:当前参与共识的所有节点身份标识
5.3.6.2. 查询验证者集合
./cmc consensus validators --sdk-conf-path=testdata/sdk_config.yml
[
"QmR5iGwXfkKwKWimuioTKEZNrEWRBsAAfueB8FncH5EhmY",
"QmSujaGs5dWBpypcHPPEgcFBjmZjW7mgg19z4rgZV33Zmq",
"QmYEQZN875VbR18YK9EYJc4zXJ6vZbQvdUjcBqqWA7rrsk",
"QmYrYkQsZz5R6XLxCZ1TXoeaGss5ccQfJnBtCDU6RAw8zR"
]
返回状态说明
返回参与共识的所有节点身份标识
5.3.6.3. 查询共识的高度
./cmc consensus height --sdk-conf-path=testdata/sdk_config.yml
{
"Height": 8
}
返回状态说明
节点当前正在共识的区块高度
5.4. TBFT
5.4.1. 算法简述
TBFT 是一种拜占庭容错的共识算法,可以在拜占庭节点数小于总数1/3的情况下,保证系统的安全运行。 TBFT 的每轮共识可以分为5个步骤:
NewRound: 共识投票的准备阶段,会初始化共识相关状态;
Proposal: 提案阶段,leader节点会打包区块,并广播给follwer节点;
Prevote: 预投票阶段,follower节点在收到proposal并验证proposal合法后,广播自己的prevote投票到其他节点;
Precommit: 预提交阶段,节点收到 >2/3 针对proposal的prevote投票后,广播自己的precommit投票到其他节点;
Commit: 提交阶段,节点收到 >2/3 针对proposal的precommit投票后,提交proposal中的区块到账本。
其中共识投票是指其中的Proposal,Prevote,Precommit三个阶段。 阶段图示如下:
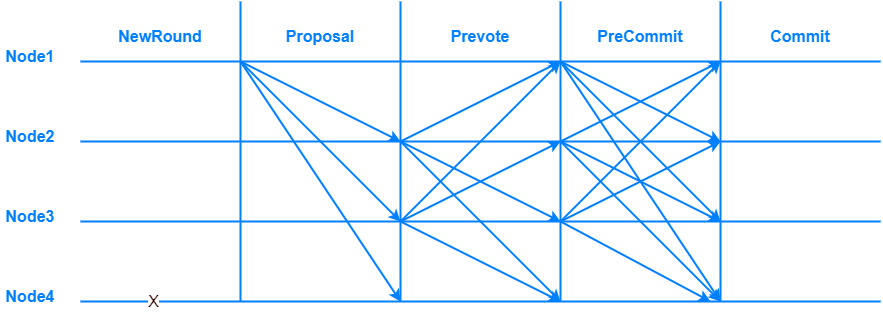
流程图如下:

5.4.2. 与PBFT的区别
TBFT基于Tendermint算法,与PBFT的最大区别在于:PBFT有一个固定的leader节点打包交易,当leader节点故障的时候会使用view-change子协议更换leader;而在TBFT中,leader是轮换的,每提交n个块(可以配置)leader会轮换成下一个节点。因此,TBFT比PBFT有更好的公平性。
TBFT实现了随机性交易的剔除,当一个交易具有随机性执行结果的时候(该交易在不同节点执行结果不一致,比如说该交易调用合约时获取一个时间戳或者产生一个随机值),TBFT可以通过共识对该交易进行剔除,从而保证链的稳定性和正确性。从节点在收到提案进行验证的时候对这种随机性的交易的读写集进行判断,如果读写集不一致,则会在发起prevote投票的时候,加上对该交易进行剔除的投票。当收集到f+1个对该交易的剔除投票,则会调用核心引擎对该交易进行剔除。
5.4.3. 与msgbus交互流程
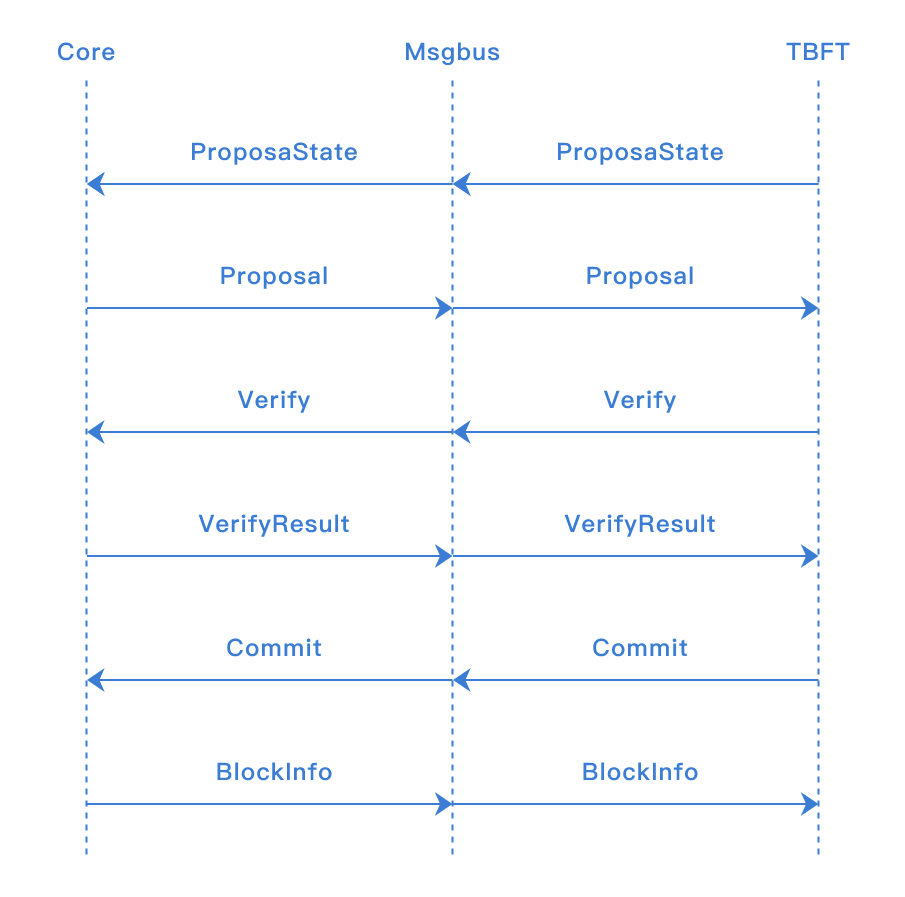
ProposaState: TBFT发送给核心引擎本节点在当前高度是否是leader节点,核心引擎判断是否需要打包区块
Proposal: 核心引擎打包区块并发送给TBFT
Verify: 当本节点收到主节点发来的区块后,向核心引擎验证区块读写集等信息
VerifyResult: 核心引擎返回给TBFT Verify的结果,当区块合法时,本节点将会投票给区块
Commit: TBFT完成共识后,向核心引擎发送提交区块的信号,核心引擎提交区块到账本
BlockInfo: 核心引擎告知TBFT已提交区块的高度等信息,TBFT进入下一个高度
5.4.4. 接口说明
TBFT 实现了长安链的ConsensusEngine接口。
Start 方法用来初始化TBFT内部状态及启动TBFT实例。
Stop 方法用来停止TBFT实例。
ConsensusState接口封装了节点共识状态的查询方法。
type ConsensusEngine interface {
// Init starts the consensus engine.
Start() error
// Stop stops the consensus engine.
Stop() error
// ConsensusState get the consensus state
ConsensusState
}
// ConsensusState get consensus state
type ConsensusState interface {
GetValidators() ([]string, error)
GetLastHeight() uint64
GetConsensusStateJSON() ([]byte, error)
GetConsensusType() consensuspb.ConsensusType
GetAllNodeInfos() []consensuspb.ConsensusNodeInfo
}
5.4.5. 数据结构
// TBFTMsgType defines different type message in tbft
enum TBFTMsgType {
propose = 0;
prevote = 1;
precommit = 2;
state = 3;
fetch_roundqc = 4;
send_round_qc = 5;
}
message TBFTMsg {
TBFTMsgType type = 1;
bytes msg = 2;
}
// Proposal defined a consesensus proposal which can
// be gossiped to other node and can be serilized
// for persistent store.
message Proposal {
string voter = 1;
uint64 height = 2;
int32 round = 3;
int32 pol_round = 4;
Block block = 5;
EndorsementEntry endorsement = 6;
map<string, common.TxRWSet> txs_rw_set = 7;
repeated Vote qc = 8;
}
// VoteType represents the type of vote
enum VoteType {
VotePrevote = 0;
VotePrecommit = 1;
}
// Vote represents a tbft vote
message Vote {
VoteType type = 1;
string voter = 2;
uint64 height = 3;
int32 round = 4;
bytes hash = 5;
EndorsementEntry endorsement = 6;
repeated string invalidTxs = 7;
}
// Step represents the step in a round
enum Step {
NewHeight = 0;
NewRound = 1;
Propose = 2;
Prevote = 3;
PrevoteWait = 4;
Precommit = 5;
PrecommitWait = 6;
Commit = 7;
}
5.4.6. 配置参数
TBFT 可以通过在配置块中的ext_config字段配置相关参数:
“TBFT_propose_timeout”: 提案的超时时间,如
10s,1m;“TBFT_propose_delta_timeout”: 每轮提案超时增加的时间,如
10s,1m;“TBFT_blocks_per_proposer”: 每个节点连续出块数,如
"3"。
5.4.7. 共识状态查询
5.4.7.1. 查询共识节点状态
./cmc consensus status --sdk-conf-path=testdata/sdk_config.yml
{
"id":"QmdTmd9taztX2Qno6mgmecYh43ZZv68vnH9KstpKZu3UyH",
"height":5,
"round":1,
"step":2,
"height_round_vote_set":{
"Sequence":5,
"round_vote_sets":{
"0":{
"Sequence":5,
"prevotes":{
"Sequence":5,
"sum":3,
"maj23":"TmlsSGFzaA==",
"votes":{
"QmQB7nFwnHnZFLV2MeHKYB22QoGm9n83rEucRAFNjjtUYd":{
"voter":"QmQB7nFwnHnZFLV2MeHKYB22QoGm9n83rEucRAFNjjtUYd",
"Sequence":5,
"hash":"TmlsSGFzaA==",
"Signature":"..."
},
"QmcfmCPRCXZcou8VcaYNKzuyipLnh1UckzXQSdRcqDoXVh":{
"voter":"QmcfmCPRCXZcou8VcaYNKzuyipLnh1UckzXQSdRcqDoXVh",
"Sequence":5,
"hash":"TmlsSGFzaA==",
"Signature":"..."
},
"QmdTmd9taztX2Qno6mgmecYh43ZZv68vnH9KstpKZu3UyH":{
"voter":"QmdTmd9taztX2Qno6mgmecYh43ZZv68vnH9KstpKZu3UyH",
"Sequence":5,
"hash":"TmlsSGFzaA==",
"Signature":"..."
}
},
"votes_by_block":{
"TmlsSGFzaA==":{
"votes":{
"QmQB7nFwnHnZFLV2MeHKYB22QoGm9n83rEucRAFNjjtUYd":{
"voter":"QmQB7nFwnHnZFLV2MeHKYB22QoGm9n83rEucRAFNjjtUYd",
"Sequence":5,
"hash":"TmlsSGFzaA==",
"Signature":"..."
},
"QmcfmCPRCXZcou8VcaYNKzuyipLnh1UckzXQSdRcqDoXVh":{
"voter":"QmcfmCPRCXZcou8VcaYNKzuyipLnh1UckzXQSdRcqDoXVh",
"Sequence":5,
"hash":"TmlsSGFzaA==",
"Signature":"..."
},
"QmdTmd9taztX2Qno6mgmecYh43ZZv68vnH9KstpKZu3UyH":{
"voter":"QmdTmd9taztX2Qno6mgmecYh43ZZv68vnH9KstpKZu3UyH",
"Sequence":5,
"hash":"TmlsSGFzaA==",
"Signature":"..."
}
},
"sum":3
}
}
}
}
}
}
}
返回状态说明 返回参数为json,各field均使用omitempty,0值或不赋值时不显示。
{
id:节点id,类型为number
height:当前共识高度,类型为string
round:当前共识轮次,类型为number
step:当前共识步骤,类型为number,0表示NewHeight,2表示Propose、3表示Prevote、5表示Precommit、7表示commit
height_round_vote_set:当前共识收到的投票集合,类型为HeightRoundVoteSet
}
HeightRoundVoteSet,表示高度内所有轮次的投票:
{
Sequence:共识高度,类型为number
round:共识轮次,类型为number
round_vote_sets:每个轮次的投票集合,类型是key为round,value为RoundVoteSet类型的map
}
RoundVoteSet,表示每个轮次的投票:
{
Sequence:投票的高度,类型为number
round:投票的轮次,类型为number
prevotes:prevote投票集合,类型为VoteSet
precommits:precommit投票集合,类型为VoteSet
}
VoteSet,表示一个投票集合:
{
type:投票类型,类型为number,0表示prevote投票,1表示precommit投票
Sequence:共识高度,类型为number
round:共识轮次,类型为number
sum:VoteSet内的投票数量,类型为number
maj23:VoteSet已达成共识(收到2/3+1张对同一个hash的投票)的投票hash,类型为string
votes:所有的投票,类型是key为节点id,value为Vote类型的map
votesByBlock:针对不同hash的投票集合,类型是key为投票hash,value为BlockVotes类型的map
}
Vote,表示一个投票:
{
type:投票类型,类型为number,0表示prevote投票,1表示precommit投票
voter:投票者,类型为string
Sequence:投票高度,类型为number
round:投票轮次,类型为number
hash:投票的hash,类型为string
Signature:投票签名,类型为string
invalidTxs:提案验证时执行结果不一致的交易的txid,类型为string数组
}
BlockVotes,表示针对某个hash的投票集合:
{
votes:投票集合,类型是key为投票者,value为Vote类型的map
sum:BlockVotes内的投票数量
}
5.4.7.2. 查询验证者集合
./cmc consensus validators --sdk-conf-path=testdata/sdk_config.yml
[
"QmQB7nFwnHnZFLV2MeHKYB22QoGm9n83rEucRAFNjjtUYd",
"QmVVqsw5VdK16rWvs4MVywhAZjoJcGvoYewLW8YdvDJmX8",
"QmcfmCPRCXZcou8VcaYNKzuyipLnh1UckzXQSdRcqDoXVh",
"QmdTmd9taztX2Qno6mgmecYh43ZZv68vnH9KstpKZu3UyH"
]
返回状态说明
返回参与共识的所有节点身份标识,类型为string数组。
5.4.7.3. 查询共识的高度
./cmc consensus height --sdk-conf-path=testdata/sdk_config.yml
{
"Height": 2
}
返回状态说明
节点当前正在共识的区块高度,类型为number。
5.5. Maxbft
consensus-maxbft模块实现了hotstuff流水线共识,是一种优化后的三阶段BFT算法,当拜占庭节点数小于共识节点数的1/3时,可以保证系统的安全、高效运行、并提供状态的最终性保证;相较于其它BFT算法在如下方面进行了优化:
优化投票流程,使用星型网络减少网络通信量至O(n)
使用流水线模式简化三阶段共识消息类型:提案消息、投票消息
活性(liveness)规则与安全性(safetyRules)规则解耦
hotstuff是一种基于view的共识算法,每个view又称为level,每次进行view切换时,更新下一个view的proposer、触发新提案的生成,具有如下特性;
共识算法运转过程中,存在两个全局累加的变量:区块高度、共识view,指定的区块高度可能经历多轮共识才达成一致,当节点生成有效区块或当前共识view超时未达成一致,共识view递增但区块高度不变
hotstuff流水线共识算法中,当前共识view提案的投票发送下一个共识view的proposer节点,由下一个view的proposer收集投票信息组成QC,包含在下一个view生成的提案中
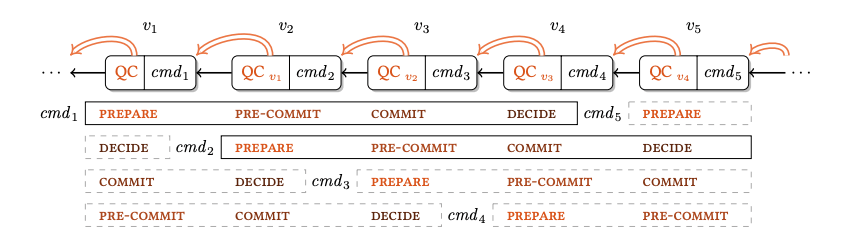
hotstuff共识算法为三阶段协议:prepareQC、precommitQC、commitQC
由于每一阶段都是对特定类型的消息收集投票,因此在流水线模式实现中,对投票流程和消息类型进行了优化,实际对每个提案只进行了一次投票共识生成prepareQC,precommitQC、commitQC作为一种逻辑上的概念,由随后子孙提案的prepareQC充当,即:当对一个提案投赞同票时,也表示赞同它的前置提案,在共识运行中,一个QC在逻辑上分别对应不同提案的不同阶段。
prepareQC:当共识节点接收视图为view的提案验证通过后,对view提案进行投票并发送给view+1的Leader,共识view+1的Leader基于view生成新提案时,将视图view投票聚合的QC包含在view+1的提案中,广播给其它共识节点,当其它共识节点收到view+1提案消息验证通过后,则表示网络中(n-f)个共识节点对视图view的提案达成第一轮共识(prepareQC)
precommitQC/lockedQC:视图view提案的precommitQC是由视图view+1提案的prepareQC间接确认的,即view+2的Leader将验证者集合对view+1提案的共识投票作为QC包含在view+2的提案中,其它共识节点收到view+2提案并验证通过时,表示对视图view+1提案的prepareQC阶段达成,对视图view提案的precommitQC阶段达成
commitQC:与precommitQC阶段达成类似,视图view提案的commitQC是通过对视图view+2提案的prepareQC间接达成的;共识节点收到视图view+2的提案、验证通过后进行投票,视图view+3的Leader接收投票聚合为QC、将其包含在view+3生成的提案中,广播给其它共识节点。当其它共识节点收到view+3的提案并验证通过时,表示链上验证集合对视图view提案的commitQC达成,此时会将view的提案提交上链、达成状态最终性
在上述三阶段中,网络中的共识消息类型被简化为2种:提案消息
ProposalData,投票消息VoteData;且将precommitQC、commitQC阶段通过下一个视图的prepareQC阶段间接达成,减少了共识的交互流程
因此hotstuff流水线共识中,节点最少会缓存三个视图(view、view+1、view+2)的待提交提案信息,直至接受视图view+3提案时,将view的提案进行提交、并标识视图view+3的提案为待提交.
名字解释
QC(quorum certificate):(n−f)个节点对指定proposal消息的签名投票集合
prepareQC:prepare阶段收集的投票集合
precommitQC:precommit阶段收集的投票集合
commitQC:commit阶段收集的投票集合
5.5.1. 模块设计
共识模块主要由几个组件组成,世代epoch、提案消息缓存服务msgcache、共识消息处理引擎engine、共识消息验证器verifier、提案消息存储服务forest、投票处理器voter、共识活性服务pacemaker、wal存储wal、节点间共识信息同步服务compensator、各模块相互配合实现maxbft流水线共识算法。
epoch:共识运行过程中由一个个epoch组成,每个epoch包含一组共识节点、在预定的视图范围内由这些共识节点生成提案、投票共识信息、驱动共识运行;每个epoch的最后一个提案初始化下一个epoch的信息,当前epoch最后一个提案被提交上链后触发世代切换
msgcache:检查网路中接收的提案消息是否缺失祖先提案,缓存缺失祖先提案的消息、并触发请求获取缺失的提案
engine:处理世代内接收到的共识消息
verifier:实现了共识消息的提案、投票验证规则
forest:缓存验证过的提案信息、并维护共识的各种QC状态genericQC、lockedQC、finalQC
voter:缓存验证过的投票信息、实现提案的投票规则
pacemaker:共识活性服务,使用接收到的QC、提案、超时信息,推进节点的共识状态
wal:在共识过程中存储验证过的共识消息
compensator: 共识内部的同步服务,发送、处理获取缺失提案的请求
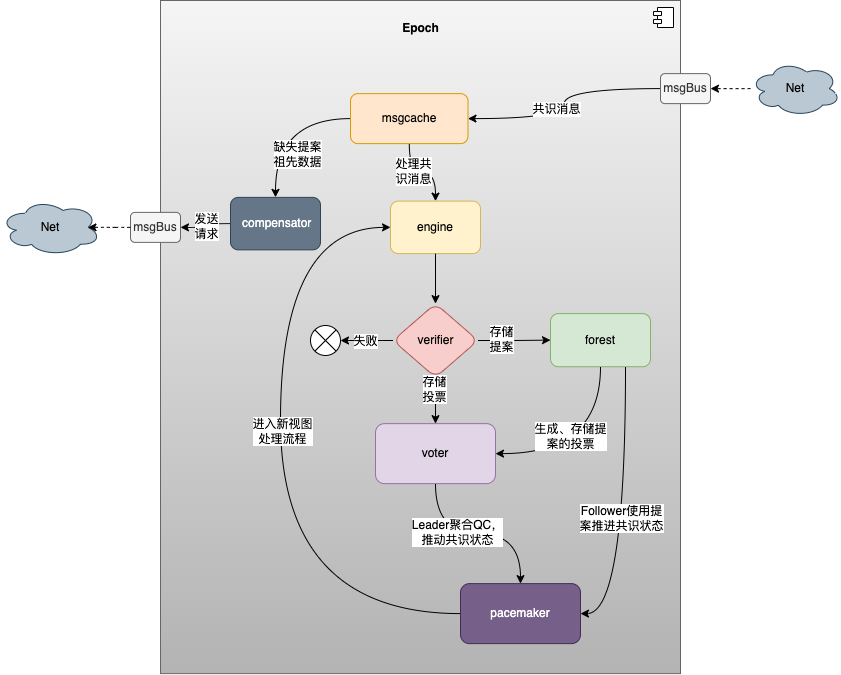
5.5.2. pacemaker 状态推进机制
pacemaker 提供了共识算法的活性,当某次共识view共识未达成一致、或共识消息处理完成后,使用相应的结果推进pacemaker维护的节点共识状态、并设置相应的超时器;因此共识的状态由两种信息推动:
共识信息:提案、投票组成的QC信息;当视图V+1的follower接受视图V的提案后,使用提案信息驱动pacemaker进入V+1的共识状态,当视图V+1的Leader接受视图V的提案后,设置超时器、进入投票收集阶段,使用投票聚合的QC信息驱动pacemaker进入V+1的共识状态
超时信息:超时器有等待提案、等待投票两种类型,当节点进入一个新视图后,设置接受提案类型的超时器,当节点作为视图proposal.View+1的Leader时,接受提案proposal后进入投票超时阶段;无论何种超时时间被触发都将驱动pacemaker进入下一个新视图
超时时间在[MaxBFTRoundTimeoutMill, MaxBFTMaxTimeoutMill] 范围内波动,通过最新提交的提案视图finalView与当前设置超时的视图currView确定当前超时类型的时间;算法为:timeOut = currView - finaView <= 4? MaxBFTRoundTimeoutMill : MaxBFTRoundTimeoutMill + MaxBFTRoundTimeoutIntervalMill * (currView - finalView - 4)
公示中常量为4的原因:一个区块的提交需要满足three-chain规则(即当前区块后接三个子孙块v+1, v+2, v+3),又因实现中设置超时器时满足three-chain的提案还未被提交(即finalView还未更新),因此正常无超时情况下currView - finalView 最大的间隔应为4
5.5.3. epoch 切换机制
epoch机制为maxbft共识算法提供了增删共识节点的功能,每个epoch创建时基于当前链配置合约chainconfig的共识节点状态初始化该epoch参与共识的节点信息,当前epoch的最后一个提案创建下一个epoch的状态,当最后一个提案被提交后触发epoch切换,同时丢弃当前epoch在该提案后的所有生成的子孙块。
提供了三种Epoch策略:基于链配置变动basedonconfig,基于区块高度basedonheight,基于共识视图baseonview,每个策略具有不同的世代切换机制,支持多种应用场景。
basedonconfig:基于链配置变动的策略,链配置变动的区块上链时触发世代切换,使新的链配置实时生效
basedonheight:基于区块高度的策略,每个世代由指定数量的区块组成,当上链的区块高度达到EndState时触发世代切换,世代期间多个链配置的变动在切换至下个世代时统一生效
basedonview:基于共识视图的策略,每个世代由最少N个视图组成,当上链的区块视图编号大于等于EndState时触发世代切换,世代期间多个链配置的变动在切换至下个世代时统一生效
5.5.4. 接口
MaxBFT 实现了长安链的ConsensusEngine接口。
Start 方法用来初始化MaxBFT内部状态及启动MaxBFT实例。
Stop 方法用来停止MaxBFT实例。
ConsensusState接口封装了节点共识状态的查询方法。
type ConsensusEngine interface {
// Init starts the consensus engine.
Start() error
// Stop stops the consensus engine.
Stop() error
// ConsensusState get the consensus state
ConsensusState
}
// ConsensusState get consensus state
type ConsensusState interface {
GetValidators() ([]string, error)
GetLastHeight() uint64
GetConsensusStateJSON() ([]byte, error)
GetConsensusType() consensuspb.ConsensusType
GetAllNodeInfos() []consensuspb.ConsensusNodeInfo
}
5.5.5. 配置参数
MaxBFTRoundTimeoutMill:共识状态初始超时时间;示例:”5000”,数值单位 ms
MaxBFTRoundTimeoutIntervalMill:每次超时后下一轮共识增加的delta时间;示例:”2000”,数值单位 ms
MaxBFTMaxTimeoutMill:超时时间上限;示例:”15000”,数值单位 ms
MaxBFTEpochStrategy: 共识采用的世代策略
MaxBFTPerEpochNumber:每个世代共识的执行状态;示例:”50”
basedonconfig策略,该字段无意义
basedonheight策略,每个世代提交指定数量的区块
basedonview策略: 每个世代至少执行的共识轮次
5.5.6. 共识状态查询
5.5.6.1. 查询共识节点状态
./cmc consensus status --sdk-conf-path=testdata/sdk_config.yml
{
"Epoch": 0,
"Height": 0,
"View": 1,
"EndState": 18446744073709551615,
"CurrViewTimeOut": "15s",
"EpochStrategy": "basedonconfig",
"Proposer": "QmSujaGs5dWBpypcHPPEgcFBjmZjW7mgg19z4rgZV33Zmq",
"Nodes": ["QmR5iGwXfkKwKWimuioTKEZNrEWRBsAAfueB8FncH5EhmY", "QmSujaGs5dWBpypcHPPEgcFBjmZjW7mgg19z4rgZV33Zmq", "QmYEQZN875VbR18YK9EYJc4zXJ6vZbQvdUjcBqqWA7rrsk", "QmYrYkQsZz5R6XLxCZ1TXoeaGss5ccQfJnBtCDU6RAw8zR"]
}
返回状态说明
Epoch:节点当前所在世代编号
Height:节点正在共识的区块高度
View: 节点的共识视图状态
EpochStrategy:当前的世代切换策略;maxbft提供了三种策略:basedonconfig、basedonheight、basedonview
basedonconfig:基于链配置变动的策略,链配置变动的区块上链时触发世代切换,使新的链配置实时生效
basedonheight:基于区块高度的策略,每个世代由指定数量的区块组成,当上链的区块高度达到EndState时触发世代切换,世代期间多个链配置的变动在切换至下个世代时统一生效
basedonview:基于共识视图的策略,每个世代由最少N个视图组成,当上链的区块视图编号大于等于EndState时触发世代切换,世代期间多个链配置的变动在切换至下个世代时统一生效
EndState:当前世代在何时结束,切换至下个世代;不同的世代策略含义不同
basedonconfig: uint64最大值,该字段无意义
basedonheight: 当前世代结束的区块高度,当上链的区块等于该高度时,触发世代切换
basedonview: 当前世代结束的视图号,当上链的区块视图号大于等于该状态时,触发世代切换
Proposer: 当前世代节点所在共识视图状态下被选举为leader的身份标识
Nodes:当前世代参与共识的所有节点身份标识
5.5.6.2. 查询验证者集合
./cmc consensus validators --sdk-conf-path=testdata/sdk_config.yml
[
"QmR5iGwXfkKwKWimuioTKEZNrEWRBsAAfueB8FncH5EhmY",
"QmSujaGs5dWBpypcHPPEgcFBjmZjW7mgg19z4rgZV33Zmq",
"QmYEQZN875VbR18YK9EYJc4zXJ6vZbQvdUjcBqqWA7rrsk",
"QmYrYkQsZz5R6XLxCZ1TXoeaGss5ccQfJnBtCDU6RAw8zR"
]
返回状态说明
返回参与共识的所有节点身份标识
5.5.6.3. 查询共识的高度
./cmc consensus height --sdk-conf-path=testdata/sdk_config.yml
{
"Height": 8
}
返回状态说明
节点当前正在共识的区块高度
5.6. DPoS
DPoS(Delegated Proof of Stake)委托权益证明共识算法,类似于公司董事会制度,在DPoS共识制度下,会选出一定数量的节点,来负责生成、验证区块。节点的选举根据节点质押的权益来进行,被选出来的节点代表其他所有的节点进行小范围共识出块。正常生产区块的节点可以获得额外的权益激励,但如果节点不履行生产区块的职责,或者作恶,会被剔除出去,并且依据事先设定的惩罚规则进行惩罚(如扣除质押的部分权益)。
DPoS共识是由DPoS委托质押算法、TBFT拜占庭共识算法组合实现的;DPoS委托质押算法负责节点的权益质押、验证人集合的选举、激励、惩罚这些操作,TBFT共识算法负责对Proposer生成的区块进行验证,保证大多数验证者节点对区块达成一致;
chainmaker【v1.2.0+版本】的DPoS共识实现是基于证书体系构建的,所以新节点准备参与共识过程时,除了DPoS共识自身所需的权益质押,还需要使用证书体系的管理机制(即:系统配置合约的操作),将新节点添加到网络中。
DPoS共识中,设置指定数量区块的区块构成一个世代,每个世代包含一批从候选人中依据质押的权益选举出来的验证者,作为世代的验证者集合,每个验证者轮流作为Proposer进行出块,其它不出块的验证者对Proposer生成的区块进行TBFT共识,保证大多数验证者对该区块达成一致,每个世代的最后一个区块选举下一个世代的验证者集合,并将选举结果写入区块以便其它验证者节点进行校验。因此在区块链上存在三种节点:普通节点、候选人节点、验证人节点;普通节点通过质押一定数量的权益资产,成为候选人节点,每个世代的最后一个区块,依据候选人质押的权益,选举一批节点作为下一个世代的验证者集合。

Note
【chainmaker v1.2.0】的DPoS共识仅支持levelDB存储引擎
【chainmaker v1.2.0】未实现区块激励、作恶惩罚,仅支持共识节点的增删、质押/解质押功能
【chainmaker v3.0.0】支持激励、作恶惩罚机制
5.6.1. 质押规则
普通节点通过质押权益成为候选人,具有如下的规则:
成为候选人的节点自身需要至少抵押该
stake.minSelfDelegation数量的权益stake.minSelfDelegation为链启动时配置的参数,候选人最少抵押的权益数量任何人/组织都可以将权益委托质押给某个候选人,候选人质押的权益数量越多,被选为验证者的几率越大
所有质押的权益会被一直冻结,直到用户退出质押且在一段时间后
stake.completionUnbondingEpochNum,所冻结的质押资产才会退还给用户stake.completionUnbondingEpochNum为链启动时配置的参数,用户退出质押后,间隔几个世代再将用户的资产退还到相应的账户用户的质押权益会转入stake合约的系统账户地址中,该系统账户地址是由合约名通过算法生成的
stakeAddress = base58(sha256(stakeContractName))
5.6.2. 验证人选举规则
每个世代会从候选人中选择一批验证者进行共识,为了在参考候选人质押资金的同时,也可以尽可能维护系统的公平性,设计了如下概率性选择算法,使所有候选人都有成为验证者的可能:
候选人的数量为M,选举的验证者集合的数量为N;依据候选人质押资金将其分为两个集合,质押资金topN的候选人为优先级集合,其余为普通集合
从优先级集合中选举N/2的节点作为验证者,剩余未被选中节点合并至普通集合,参与剩余的N/2个验证者的选举
5.6.3. 接口
type DPoS interface {
CreateDPoSRWSet(preBlkHash []byte, proposedBlock *consensuspb.ProposalBlock) error
VerifyConsensusArgs(block *common.Block, blockTxRwSet map[string]*common.TxRWSet) error
GetValidators() ([]string, error)
}
CreateDPoSRWSet: 依据节点提案的区块和链上数据,生成DPoS共识的读写集,并将读写集添加至区块中VerifyConsensusArgs: 验证区块中包含的DPoS读写集是否正确GetValidators: 获取当前世代的验证者
5.6.4. 系统合约
DPoS有多个系统合约:
ERC20系统合约: 存储链上所有用户的资产,并处理权益的转移、增发等逻辑;
Stake系统合约:存储共识中的质押、退出质押、世代(每个世代包含验证者集合、下一个世代的创建高度)等信息,并处理用户的质押、退出质押、关联NodeID逻辑;
Distribution合约:计算每个块产出的激励权益数量,激励给产出该块的共识节点。
Slashing合约:在世代中未完成既定出块数的共识节点,计算惩罚权益数量,并从Stake合约中质押数量中扣减到Slashing账户地址中。
注意:关联NodeID操作的原因,NodeID是由节点证书内包含的公钥生成的,用于表示节点在链上的身份,且验证者生成的区块是用该证书对应的私钥进行签名的, 因此该私钥需要放置在运行节点的服务器上;为了保证用户质押资金的安全,使用了另一套证书来标示用户的身份,用户的资金存储在该证书内公钥生成的地址上, 该证书可以离线存储,以保证资金的安全。
因此,节点质押资金成为候选人时,需要先在链上关联用户质押地址对应的NodeID。
5.6.5. 配置参数
consensus:
# 共识类型(0-SOLO, 1-TBFT, 3-MAXBFT, 4-RAFT, 5-DPOS, 6-ABFT)
type: 5
dpos_config:
#ERC20合约配置
- key: erc20.total
value: "1250000000000000000000000"
- key: erc20.owner
value: "4WUXfiUpLkx7meaNu8TNS5rNM7YtZk6fkNWXihc54PbM"
- key: erc20.decimals
value: "18"
- key: erc20.account:SYSTEM_CONTRACT_DPOS_STAKE
value: "1000000000000000000000000"
- key: erc20.account:4QUXfiUpNmj7meaNu8TNS5rNM7YtZk6fkNWXihc589kN
value: "250000000000000000000000"
#Stake合约配置
- key: stake.minSelfDelegation
value: "25000000000000000000000"
- key: stake.epochValidatorNum
value: "4"
- key: stake.epochBlockNum
value: "12" #必须是epochValidatorNum的整数倍
- key: stake.completionUnbondingEpochNum
value: "1"
- key: distribution.fromSlashing
value: "false"
- key: distribution.perBlock
value: "100"
- key: distribution.gasExchangeRate
value: "1"
- key: slashing.perBlock
value: "100"
- key: stake.candidate:4WUXfiUpLkx7meaNu8TNS5rNM7YtZk6fkNWXihc54PbM
value: "250000000000000000000000"
......
- key: stake.nodeID:4WUXfiUpLkx7meaNu8TNS5rNM7YtZk6fkNWXihc54PbM
value: "QmRmTtfm7w5KwVAJALLU23y9TyiCNTUiqVbcErfBqhenrh"
......
erc20.total: ERC20合约发行权益的总量erc20.owner: ERC20合约的管理员,拥有增发权益的权利erc20.decimals: ERC20合约中权益的精度erc20.account:<addr>: ERC20合约中创世块时每个账户所拥有的资金SYSTEM_CONTRACT_DPOS_STAKE: 由于stake合约地址是由合约名通过sha256计算后base58编码得到的,为固定值;但base58的值可读、可写不便,容易配置出错,因此,对于stake合约的地址配置为合约名;链启动后可以通过该命令查询stake合约地址其它的账户的初始资金配置,使用用户的地址进行配置
stake.minSelfDelegation: 候选人自身SYSTEM_CONTRACT_DPOS_STAKE最少质押的权益数量stake.epochValidatorNum: 每个世代验证者的数量stake.epochBlockNum: 每个世代的区块数量stake.completionUnbondingEpochNum:用户退出质押后间隔几个世代将资金退还给用户stake.candidate:<addr>: 创世块时每个候选人质押的资金stake.nodeID:创世块时每个候选人关联的NodeIDdistribution.perBlock: 每次出块激励的权益数量, 如果设置为0,表示不激励distribution.fromSlashing: 激励数量是否使用惩罚地址余额。”true”表示使用,默认”false”表示不适用slashing.perBlock:世代内未完成出块,每个块惩罚的权益数量,如果设置为0,表示不惩罚distribution.gasExchangeRate:Gas兑换权益的比例,默认为1表示1:1兑换成激励数量。参数只能是正整数
5.6.5.1. 奖惩机制
奖惩机制是在3.0.0版本后发布,用于支持验证者出块工作的激励,和对验证者未完成既定出块任务进行惩罚。
激励:
通过对
distribution.perBlock参数不为0的配置,表示验证者每次出块后,都会得到对应的激励权益数量作为奖励。参数为0表示不对验证者进行激励。
每个
块进行一次激励例如:配置为
100的时候,表示每次出块后,会对出块的验证者直接激励100的权益到节点账户余额中。
惩罚:
通过对
slashing.perBlock参数不为0的配置,表示验证者未完成世代中既定的出块数量,每少出一个块进行的惩罚额。参数为0表示不对验证者进行惩罚。
每个
世代进行一次惩罚每次惩罚扣除验证者总质押额,同时按照比例扣除每个参与质押的质押者的质押额
例如:配置为
100的时候,如果验证者在一个世代中少出了1个块,则直接从该验证者的质押权益中,扣除100权益到slashing地址上。
既定出块数: 世代中每个共识节点(验证者)根据参数配置计算出的出块数量。
在一个世代中,总出快数/验证者数量 = 每个验证者既定出块数(每个共识节点的既定出块数)
stake.epochBlockNum:每个世代的区块数量;stake.epochValidatorNum: 每个世代验证者的数量
参数要求: 每个世代的区块数量epochBlockNum 必须是 每个世代验证者的数量epochValidatorNum 的整数倍。
惩罚的比例计算
假设节点A为验证者,总质押权益为1000。 分别是来自 A自我质押的800和B节点质押给A的200。因此A和B质押比例为:4:1。
当世代切换的时候,触发了惩罚机制,验证者A总质押权益数会被扣除100,则总质押权益数为:900。 同时会按照4:1比例将A和B的质押权益数分别调整为:720 和180。
这时,B节点要进行解除质押的时候,可解除的最大权益数就只有180。
5.6.5.2. Gas兑换
兑换方式:启用Gas的情况下,每笔交易支付的gas按照比例兑换成权益激励给出块的节点。
默认:distribution.gasExchangeRate = 1
例如: 假设 每个块交易gas总和为: 100
gasExchangeRate=1 时,兑换权益数:100/1 = 100
gasExchangeRate=2 时,兑换权益数:100/2 = 50
gasExchangeRate=4 时,兑换权益数:100/4 = 25
5.6.6. 节点管理
DPoS共识允许用户在链创世运行后,通过质押/解质押权益来动态的参与/退出区块链共识;用户通过质押、解质押参与共识的指引步骤见该章节。
5.6.7. 共识状态查询
5.6.7.1. 查询共识节点状态
./cmc consensus status --sdk-conf-path=testdata/sdk_config_pk.yml
{
"EpochInfo":{
"proposer_vector":[
"0981a260ae09752e73f93d46c23ce92e1206c555",
"4ad6e2a2bc63f17bf275cbae4da869cdee4eb2ed",
"7258f6710d68f5438a96db3e3e8408802823ea4a",
"e60c5bb4de2b6c57ccf4d510dfeb0cf08566f916"
],
"next_epoch_create_height":12
},
"CandidateInfos":[
{
"NodeId":"QmNvjv8Pbpc2CDdVgn6jLsk7aYvQJHzqkNzGFSLidTgBP7",
"StakeWeight":"2500000",
"CandidateAddr":"0981a260ae09752e73f93d46c23ce92e1206c555"
},
{
"NodeId":"QmUVimtg1o9UrFaZwDsVMGfhsv8QRtYwdndovt1vxqU1mi",
"StakeWeight":"2500000",
"CandidateAddr":"4ad6e2a2bc63f17bf275cbae4da869cdee4eb2ed"
},
{
"NodeId":"QmXRzi2FTP2wBFH5cWeMnGnYgC4vz6avSQe4uMjTmz7j3P",
"StakeWeight":"2500000",
"CandidateAddr":"7258f6710d68f5438a96db3e3e8408802823ea4a"
},
{
"NodeId":"QmbsxcCud7M4MdXdfSgMqESpT617PkUWriQnezZNPUczzM",
"StakeWeight":"2500000",
"CandidateAddr":"e60c5bb4de2b6c57ccf4d510dfeb0cf08566f916"
}
],
"InternalConsensusState":"eyJpZCI6IlFtWFJ6aTJ……省略部分内容……0R2hpZ2UifX0sInN1bSI6M319fX19fX0="
}
返回状态说明 返回参数为json,各field均使用omitempty,0值或不赋值时不显示
EpochInfo,表示当前世代信息:
{
proposer_vector:本世代中提案者
next_epoch_create_height:下一个世代创建时的区块高度
}
CandidateInfos,表示候选人信息:
{
NodeId:节点编号
StakeWeight:总的质押数量
CandidateAddr:候选人地址
}
InternalConsensusState,表示内部共识信息(当前使用tbft共识),该数据和tbft共识中'共识状态查询'内容相同,本处数据格式为[]byte
5.6.7.2. 查询验证者集合
./cmc consensus validators --sdk-conf-path=testdata/sdk_config_pk.yml
[
"QmR5iGwXfkKwKWimuioTKEZNrEWRBsAAfueB8FncH5EhmY",
"QmSujaGs5dWBpypcHPPEgcFBjmZjW7mgg19z4rgZV33Zmq",
"QmYEQZN875VbR18YK9EYJc4zXJ6vZbQvdUjcBqqWA7rrsk",
"QmYrYkQsZz5R6XLxCZ1TXoeaGss5ccQfJnBtCDU6RAw8zR"
]
返回状态说明
返回参与共识的所有节点身份标识
5.6.7.3. 查询共识的高度
./cmc consensus height --sdk-conf-path=testdata/sdk_config_pk.yml
{
"Height": 8
}
返回状态说明
节点当前正在共识的区块高度
5.7. ABFT
ABFT(Asynchronous Byzantine Fault Tolerance) 异步拜占庭容错共识算法,能够在异部网络环境,拜占庭节点小于总节点数1/3时,保证系统的安全运行。ABFT基于HoneyBadger BFT共识算法,HoneyBadger BFT的核心创新点在于发现了在异步、拜占庭环境下,原子广播ABC(Atomic Broadcast) 问题可以分解为分解成一个核心模块异步共同子集ACS(Asynchronous Common Subset),然后将 ACS 分解成了可靠广播 RBC(Reliable Broadcast) + 拜占庭二进制共识BBA(Byzantine Binary Agreement)两个子模块,并且分别针对这两个子模块找到了两个比较优化的实现。
通过模块化的设计,保证了在异步、拜占庭环境下,各个节点按相同顺序收到相同的消息。
异步网络模型是ABFT共识的重要特性,同步、半同步、异步是节点之间消息传输的底层网络模型。
同步网络
(synchronous):假设网络中的消息能够在一个已知的时间 Δ 内到达。即最大消息延迟是确定。比如Bitcoin、Ethereum基于的Pow共识协议,一致性和活性都采用同步假设半同步网络
(partially synchronous):网络中消息某限定时间后到达所有共识节点的的概率与时间的关系是已知的,假设在一个 GST(global stabilization time)事件之后,消息在 Δ 时间内到达。比如Raft、PBFT 都是基于半同步网络假设设计的共识协议,这些协议的关注点可以更多的放在安全性(safety),活性由 failure detector 来保证。在 PBFT 中每个 replica 都要维护一个 timer,一旦 timeout 就会触发 view change 协议选举新的 leader。这里的 timer 就起到了一个 failure detector 的作用。这些协议虽然能够保证在任何网络情况下系统的安全性,但在异步网络下会丧失活性异步网络
(asynchrony):正常节点发出消息,在一个时间间隔内可以送达目标节点,但是该时间间隔未知,即最大消息延迟未知。异步共识协议则完全不需要考虑 timer 的设置。为了保证协议的活性,异步协议需要引入随机源,简单来说就是当协议无法达成共识的时候,借助上帝抛骰子的方式随机选择一个结果作为最终结果
5.7.1. 模块设计
ABFT共识模块具体实现主要由以下几个组件组成,分别是:异步共同子集 ACS、可靠广播 RBC、拜占庭二进制共识 BBA、消息传输 msgSender,组件之间互相配合在 ConsensusABFTImpl 实现了ABFT共识算法。
异步共同子集
ACS(Asynchronous Common Subset):用于让各个节点按相同顺序收到相同的消息,每个节点的数据集合分别是U1, U2, …, Un,节点之间通过一些通讯之后每个节点上都得到一个相同的集合U=U1∪U2 … ∪Un可靠广播
RBC(Reliable Broadcast):用来确保源节点发送的交易批次能够可靠地发送到网络中的所有节点拜占庭二进制共识
BBA(Byzantine Binary Agreement):在所有节点之间进行一轮共识,让所有节点对于 0 或 1 达成一致,得到一个最终确认的二进制数值,由这个二进制的对应的位来决定哪个交易批次会被最终确认消息发送者
msgSender(Message Sender):实现了节点之间消息发送、接受的逻辑
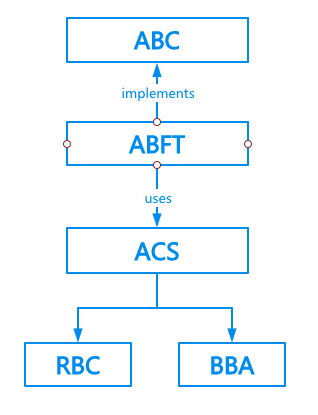
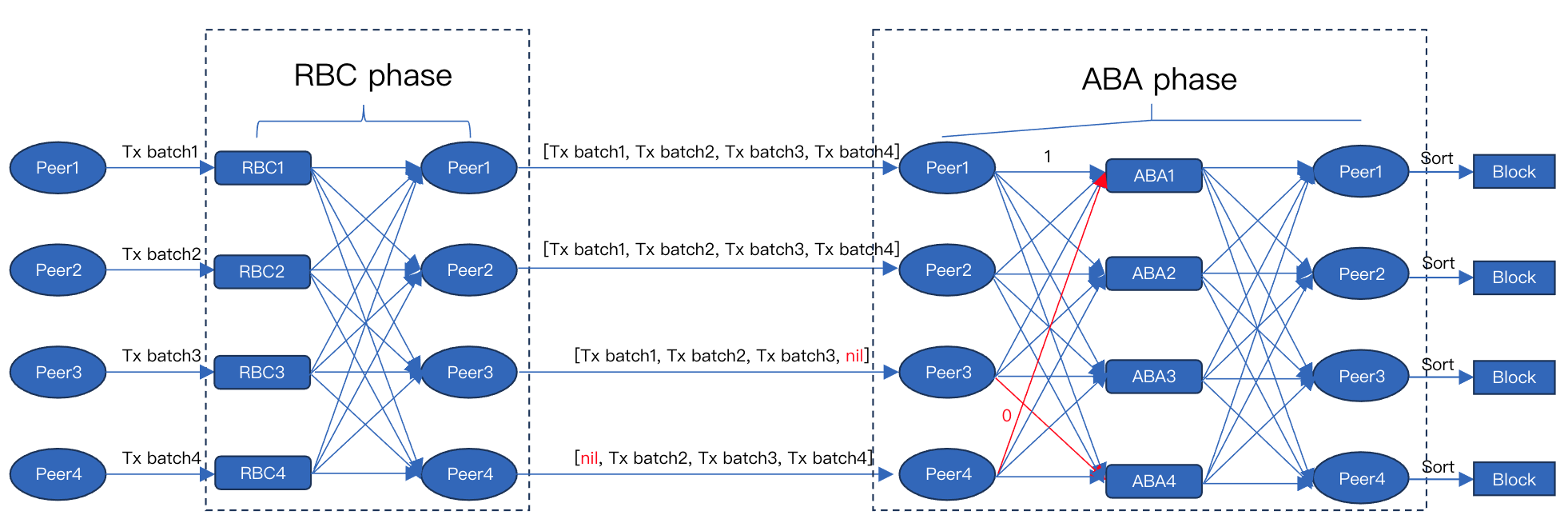
5.7.2. 共识流程
ABFT 的共识流程如下图所示,ABFT共识利用异步共同子集 ACS 实现原子广播 ABC 的。ABFT共识不区分主节点和从节点,所有节点都公平的接受交易,每个节点都随机从自己的交易池选取一批交易为一个区块贡献一部分交易,可靠广播 RBC 模块确保每个节点贡献的交易批次能够达到所有节点,拜占庭二进制共识BBA 模块的作用就是确定哪些节点贡献的交易批次最终达成共识,被包含在区块中。
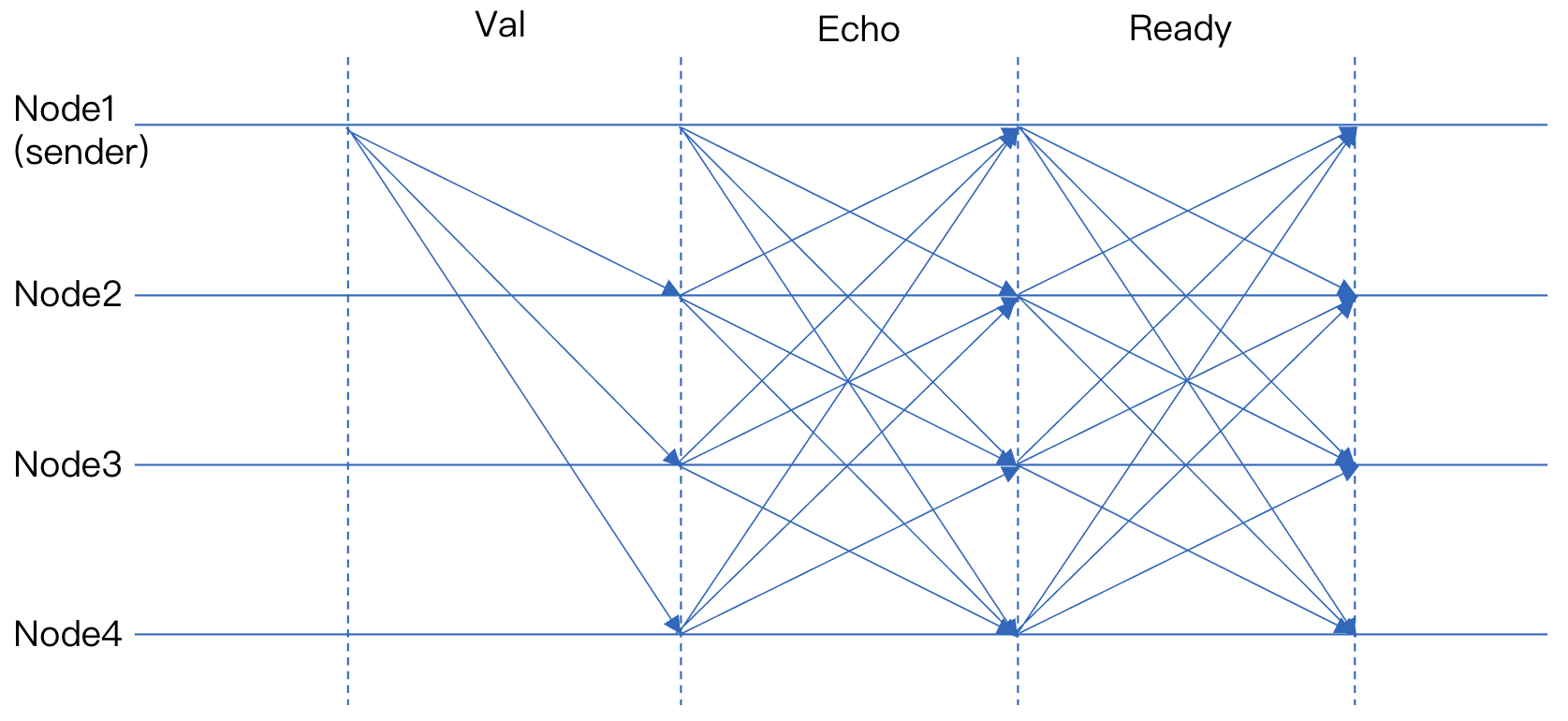
5.7.3. 可靠广播 RBC
可靠广播
RBC可以确保源节点能够可靠地将消息发送到网络中的所有节点。具体来说,RBC主要有以下三个性质:一致性(Agreement)任意两个正确节点都收到来自源节点的相同的消息
全局性(Totality)只要有一个节点收到了来自源节点的消息,那么所有正确的节点最终都能收到这个消息
有效性(Validity)如果源节点是正确的,那么所有正确的节点收到的消息一定与源节点发送的消息一致
RBC 主要分成
Val、Echo、Ready三个阶段,其中后两个阶段各经历一次 all-to-all 的广播。RBC协议通过纠删码算法降低节点间的数据传输,ABFT 中采用了基于(N-2f,N)的纠删码模式,即将一个数据块进行编码后,可以将其分成 N 份,其中只要任意 N-2f 份组合可以恢复整个数据块。
5.7.4. 拜占庭二进制共识 BBA
正确的
Byzantine Binary Agreement算法应该满足以下三个条件:Agreement:任意一个诚实节点输出b,那么所有诚实节点都输出b
Validity:任意一个诚实节点输出b,那么至少一个诚实节点的输入是b
Termination:如果所有诚实节点都有输入,那么所有诚实节点都会有输出
BBA 的实现原理:BBA完成一次需要超过2/3的参与节点同意是否在区块中包含某批次交易。如果只收到1/3-2/3的节点之间投票Y,节点无法达成一致,BBA需要借助外部随机源做决定才能正确终止。这个随机源就是 BBA 的核心组件
(Common Coin,CC),我们也可以将 CC 理解成抛硬币,只有 0 和 1 两个值。只抛一次硬币可能还是无法达成共识,那么就不停掷,最终会出现所有人都达成一致的结果。Common Coin 有很多实现方案,ABFT针对其模块化的设计,采用了基于阈值签名的 CC 方案。每个节点对一个共同的字符串进行签名并广播给其它节点,当节点收到来自其它 f+1 个节点的签名时,就可以将这些签名聚合成一个签名,并将这个签名作为随机源。
5.7.5. 门限加密(Threshold Encrytion)
因为恶意节点的存在可能干扰
Binary Byzantine Agreement的结果。因此,ABFT 提出了门限加密的方式来避免最终的交易集受到攻击。门限加密的原理是允许任何节点使用一把主公钥来加密一条信息,但是解密则需要网络中所有节点来共同合作,只有当 f + 1 个诚实节点共同合作才能获得解密秘钥,从而得到消息原文。在这之前,任何攻击者都无法解密获得消息的原文。
具体过程如下:
TPKE.Setup(1<sup>λ</sup>)→PK,{SK<sub>i</sub>}:创建一把公钥PK、同时为每个节点生成一个私钥SKi。TPKE.Enc(PK,m)→C:用这把公钥PK对明文m进行加密,加密结果是C。TPKE.DecShare(SK<sub>i</sub>,C)→σ<sub>i</sub>:每个节点用其私钥SKi 解密C得到中间结果σi。TPKE.Dec(PK,C,{i,σ<sub>i</sub>})→m:用f+1 个中间结果σi 配合PK,就可以解密C得到明文m。
注:当前chainmaker 版本未实现门限加密
5.7.6. 配置参数
#共识配置
consensus:
# 共识类型(0-SOLO, 1-TBFT, 3-MAXBFT, 4-RAFT, 5-DPOS, 6-ABFT)
type: 6